
- Powerful,
evidence-based analysis by one of the deans of American politics on how
Russian interference likely tilted the 2016 election to Donald Trump
- Marshals unique
polling data and rigorous media framing analysis to explain why in all
probability the interference had an effect on the outcome
- Provides a qualified
yet compelling answer in the affirmative to the biggest question left over
from the election: Did the Russians help elect Donald Trump?
- Carefully lays out
the challenges to the notion that the Russians tilted the election and
methodically dispenses with them
- The right to be informed as to what data will be collected, and
how it will be used
- The right to opt out of data collection or sharing
- The right to be told if a website has data on you, and what that
data is
- The right to be forgotten; to have all data related to you deleted
upon request
- The right to be informed if ownership of your data changes
hands
- The right to be informed of any data breaches including your
information in a timely manner
- The right to download all data in a standardized format to port to
another platform
Alarm bell about the threat to digital civilization as a result of
uncontrolled evolution of artificial intelligence!
In the Camps: China's
High-Tech Penal Colony
by Darren Byler
How China used a network of surveillance to
intern over a million people and produce a system of control previously unknown
in human history
Novel forms of state violence and colonization
have been unfolding for years in China’s vast northwestern region, where more
than a million and a half Uyghurs and others have vanished into internment
camps and associated factories. Based on hours of interviews with camp
survivors and workers, thousands of government documents, and over a decade of
research, Darren Byler, one of the leading experts on Uyghur society and
Chinese surveillance systems, uncovers how a vast network of technology
provided by private companies―facial surveillance, voice recognition,
smartphone data―enabled the state and corporations to blacklist millions of
Uyghurs because of their religious and cultural practice starting in 2017.
Charged with “pre-crimes” that sometimes consist only of installing social
media apps, detainees were put in camps to “study”―forced to praise the Chinese
government, renounce Islam, disavow families, and labor in factories. Byler
travels back to Xinjiang to reveal how the convenience of smartphones have
doomed the Uyghurs to catastrophe, and makes the case that the technology is
being used all over the world, sold by tech companies from Beijing to Seattle
producing new forms of unfreedom for vulnerable people around the world.
https://www.goodreads.com/en/book/show/58393878-in-the-camps
Living with Digital Surveillance in China: Citizens’ Narratives on
Technology, Privacy, and Governance
- July
2023
Authors: Ariane
Ollier-Malaterre
Abstract
Digital surveillance is a daily and all-encompassing reality of
life in China. This book explores how Chinese citizens make sense of digital
surveillance and live with it. It investigates their imaginaries about
surveillance and privacy from within the Chinese socio-political system. Based
on in-depth qualitative research interviews, detailed diary notes, and
extensive documentation, Ariane Ollier-Malaterre attempts to ‘de-Westernise’
the internet and surveillance literature. She shows how the research participants
weave a cohesive system of anguishing narratives on China’s moral shortcomings
and redeeming narratives on the government and technology as civilising forces.
Although many participants cast digital surveillance as indispensable in China,
their misgivings, objections, and the mental tactics they employ to dissociate
themselves from surveillance convey the mental and emotional weight associated
with such surveillance exposure. The book is intended for academics and
students in internet, surveillance, and Chinese studies, and those working on
China in disciplines such as sociology, anthropology, social psychology,
psychology, communication, computer sciences, contemporary history, and
political sciences. The lay public interested in the implications of technology
in daily life or in contemporary China will find it accessible as it
synthesises the work of sinologists and offers many interview excerpts…: https://www.researchgate.net/publication/372792850_Living_with_Digital_Surveillance_in_China_Citizens'_Narratives_on_Technology_Privacy_and_Governance
How China’s citizens are coping with digital surveillance
Deep learning framework for subject-independent emotion detection using wireless signals
Emotion states recognition using wireless signals is
an emerging area of research that has an impact on neuroscientific studies of
human behaviour and well-being monitoring. Currently, standoff emotion
detection is mostly reliant on the analysis of facial expressions and/or eye
movements acquired from optical or video cameras. Meanwhile, although they have
been widely accepted for recognizing human emotions from the multimodal data,
machine learning approaches have been mostly restricted to subject dependent
analyses which lack of generality. In this paper, we report an experimental
study which collects heartbeat and breathing signals of 15 participants from
radio frequency (RF) reflections off the body followed by novel noise filtering
techniques. We propose a novel deep neural network (DNN) architecture based on
the fusion of raw RF data and the processed RF signal for classifying and
visualising various emotion states. The proposed model achieves high
classification accuracy of 71.67% for independent subjects with 0.71, 0.72 and
0.71 precision, recall and F1-score values respectively. We have compared our
results with those obtained from five different classical ML algorithms and it
is established that deep learning offers a superior performance even with
limited amount of raw RF and post processed time-sequence data. The deep
learning model has also been validated by comparing our results with those from
ECG signals. Our results indicate that using wireless signals for stand-by
emotion state detection is a better alternative to other technologies with high
accuracy and have much wider applications in future studies of behavioural
sciences.
https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0242946
Spotify wants to know your "emotional
state, gender, age, or accent"
BY WREN GRAVES
ON JANUARY 28, 2021,
11:44PM
If you listen to Spotify, then soon enough Spotify may listen to you.
Via Music Business Worldwide, the streaming platform has
secured a patent to monitor the background noise and speech of its users.
The big green circle first
filed a patent for its “Identification of taste attributes from an audio
signal” product in February of 2018, and finally received approval on
January 12th, 2021. The goals is to gauge listener’s “emotional state, gender,
age, or accent,” in order to recommend new music...: https://consequenceofsound.net/2021/01/spotify-patent-monitor-users-speech/
In this masterwork of original thinking and research, Shoshana Zuboff provides startling insights into the phenomenon that she has named surveillance capitalism. The stakes could not be higher: a global architecture of behavior modification threatens human nature in the twenty-first century just as industrial capitalism disfigured the natural world in the twentieth.
The global AI race
and defense's new frontier
Driving artificial
intelligence in defense
Navigating the AI
revolution in defense
As artificial
intelligence (AI) rapidly advances, its transformative impact on industries
worldwide is undeniable, and the defense sector is no exception. Unlike past
technological shifts, AI is not merely a tool but a catalyst for entirely new
paradigms. Its applications go beyond enhancing operational efficiency,
offering capabilities that fundamentally redefine mission effectiveness, speed,
precision, and the scale of military operations.
This report delves
into AI's transformative potential in defense, exploring its influence on
military capabilities and assessing the emerging race for AI dominance. It
showcases the diverse applications of AI, from predictive analytics and
autonomous systems to robust cyber defense and intelligence-gathering.
These innovations
are poised to become central to maintaining military superiority in an
increasingly complex and interconnected global environment. The report also
addresses the critical ethical and operational challenges that accompany AI's
development and adoption, emphasizing the need for responsible AI practices in
defense as a foundation for global legitimacy and trust. AI as an
exponential driver of military capabilities
Modern militaries
operate within an environment of unprecedented complexity, where the volume of
available data, the speed of technological change, and the sophistication of
adversarial strategies continue to grow at an exponential rate. Traditional
decision-making processes, often constrained by human cognitive limits,
struggle to keep pace with the continuous influx of intelligence reports,
sensor feeds, and cyber threat alerts saturating today’s strategic and
operational landscapes.
In response to
these challenges, artificial intelligence has emerged as a key enabler of
next-generation defense capabilities, offering militaries the potential to
identify meaningful patterns hidden within massive datasets, anticipate
critical logistical demands, and detect hostilities before they materialize.
Furthermore, multi-domain operations – integrating land, air, maritime, cyber,
and space capabilities – are increasingly reliant on AI to ensure coordinated
action across these interconnected arenas. AI-driven solutions promise to
enhance the agility and resilience of armed forces as they contend with
complex, multi-domain threats.
As highlighted by
NATO and other defense organizations, the integration of AI into multi-domain
operations represents a transformative shift that amplifies the scope and
efficacy of military capabilities across all domains. Failure to integrate
risks undermining the full potential of AI in defense, leaving forces
vulnerable in environments where dominance is increasingly dictated by
technological superiority.
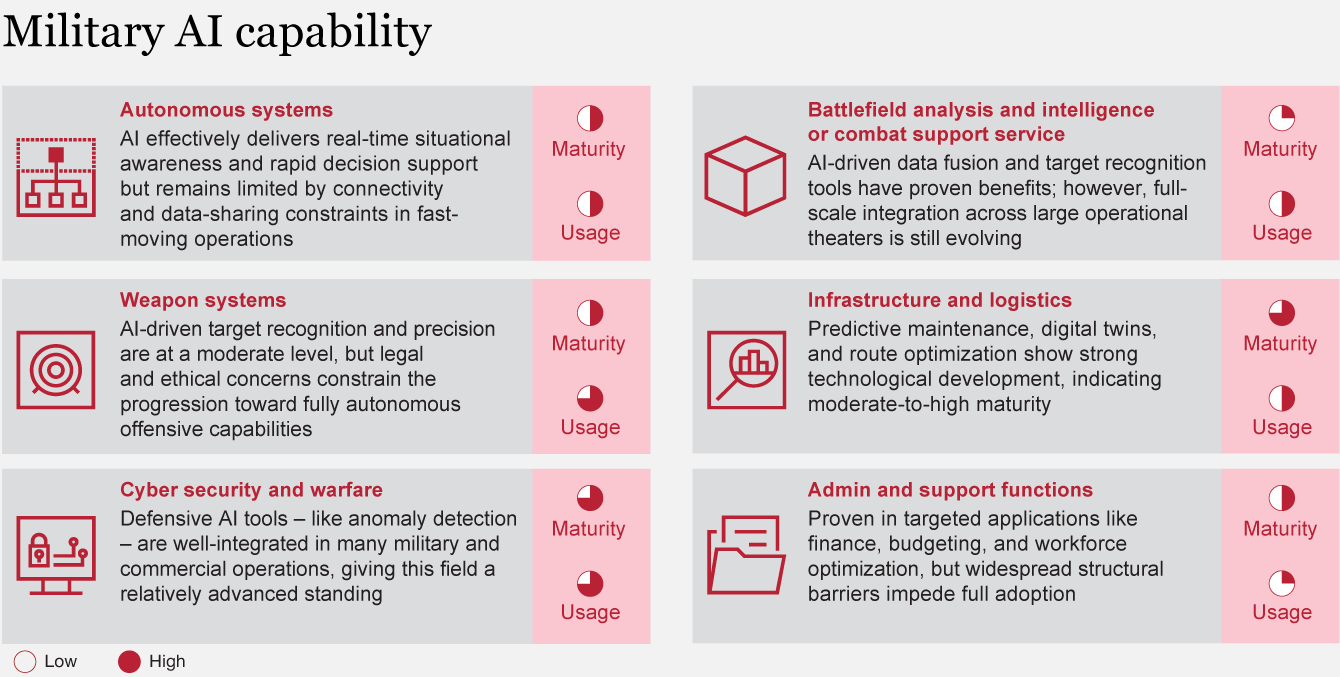
The main potential
lies in the synergy created by AI-driven collaboration across military systems,
which holds the promise of securing battlefield superiority. The following
areas highlight where AI is making remarkable strides, providing immediate and
tangible benefits to defense stakeholders through demonstrable progress and
operational maturity:
{kind=link}
Global ambitions
and the race for AI leadership
With the vast
potential of AI in defense and its current applications on the battlefield,
understanding who leads in the global AI defense race is crucial. In today's
multi-polar and crisis-laden environment, gaining insight into the strategic
priorities, technological advancements, and competitive dynamics is essential
for shaping the future of military capabilities worldwide. Below are key
factors that determine a country's position in this high-stakes race:
- 1.
AI-readiness: This factor
encompasses the technological maturity and sophistication of AI technologies
that have been developed and deployed. It also includes the integration of AI
into military doctrine, highlighting the extent to which AI has been infused
into defense strategies and combat operations.
- 2.
Strategic
autonomy: This refers to a nation's ability to independently develop and
deploy AI technologies without relying on foreign suppliers. It also considers
the scale and focus of investments in AI research, particularly in
defense-specific applications.
- 3.
Ethics and
governance: This aspect involves balancing the drive for innovation with
ethical considerations and global norms, ensuring that AI development aligns
with responsible practices.
Vision and impacts
of AI-driven defense
The integration of
AI into defense systems is revolutionizing military operations, paving the way
for a future marked by enhanced efficiency, precision, and adaptability. By
2030, AI technologies are anticipated to play a crucial role in reshaping how
defense organizations manage resources, make decisions, and execute complex
missions across various domains. From optimizing supply chains and automating
battlefield operations to empowering decision-makers with predictive insights,
AI is set to become an indispensable force multiplier. These are the key areas
where AI's impact will be most transformative:
Predictive
decision-making
Collaborative
autonomous systems
Dynamic resource
management
However, the
deployment of AI in defense comes with significant risks and potential
conflicts of interest, which could lead to strategic fragmentation and
stagnation in AI deployment. Therefore, the utilization of AI must be carefully
evaluated and deliberately managed to ensure that its deployment aligns with
the core values of democratic norms and systems within the Western alliance.
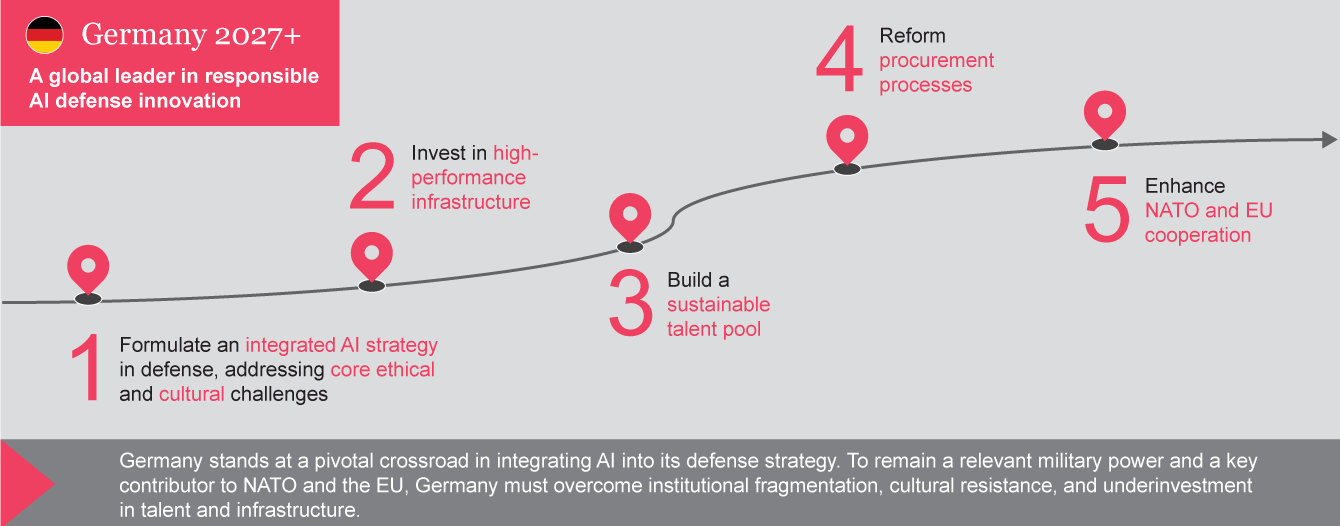
Vision 2027+: A
roadmap for Germany
Germany stands at
a critical crossroads in its defense strategy, where integrating AI is not just
an option but a necessity. To establish itself as a leader in responsible
AI-driven defense, Germany must develop a clear, action-oriented roadmap that
addresses its challenges while leveraging its strengths. This vision for 2027
and beyond is built on four key priorities: AI sovereignty, NATO and EU
interoperability, fostering innovation ecosystems, and leadership in ethical AI
governance.
Achieving these
goals will involve a phased approach. Between now and 2027, Germany's focus
should be on creating the right environment for AI integration, testing pilot
projects, and scaling successful initiatives to full operational capabilities.
By following this roadmap, Germany can position itself as a leader in
responsible AI for defense, aligning operational effectiveness with ethical
standards:
{kind=link}
Navigating the AI
frontier
Artificial
intelligence is reshaping the way nations approach defense, strategy, and
security in the 21st century. By 2030, the integration of AI technologies in
areas such as predictive decision-making, collaborative autonomous systems, and
dynamic resource management is set to revolutionize military operations,
offering unprecedented precision, agility, and resilience.
To harness AI's
full potential while mitigating risks, defense organizations must prioritize
the establishment of robust ethical frameworks, transparent accountability
mechanisms, and international collaboration. These initiatives will ensure the
responsible use of AI and maintain trust and legitimacy in the global security
arena.
To continue being
a significant military power and a key player in NATO and the EU, Germany must
act decisively to address institutional fragmentation, cultural resistance, and
underinvestment in talent and infrastructure. By leveraging its world-class research
institutions, industrial expertise, and international partnerships, Germany can
create an AI defense ecosystem founded on ethical governance and innovation.
https://www.strategyand.pwc.com/.../ai-in-defense.html
May 7, 2025
Introducing OpenAI
for Countries
A new initiative
to support countries around the world that want to build on democratic AI
rails.
Our Stargate
project, an unprecedented investment in America’s AI infrastructure
announced in January with President Trump and our partners Oracle and SoftBank,
is now underway with our first supercomputing campus in Abilene, Texas, and
more sites to come.
We’ve heard from
many countries asking for help in building out similar AI infrastructure—that
they want their own Stargates and similar projects. It’s clear to everyone now
that this kind of infrastructure is going to be the backbone of future economic
growth and national development. Technological innovation has always driven
growth by helping people do more than they otherwise could—AI will scale human
ingenuity itself and drive more prosperity by scaling our freedoms to learn,
think, create and produce all at once.
We want to help
these countries, and in the process, spread democratic AI, which means the
development, use and deployment of AI that protects and incorporates
long-standing democratic principles. Examples of this include the freedom for
people to choose how they work with and direct AI, the prevention of government
use of AI to amass control, and a free market that ensures free competition.
All these things contribute to broad distribution of the benefits of AI,
discourage the concentration of power, and help advance our mission. Likewise,
we believe that partnering closely with the US government is the best way to
advance democratic AI.
Today, we’re
introducing OpenAI for Countries, a new initiative within the Stargate project.
This is a moment when we need to act to support countries around the world that
would prefer to build on democratic AI rails, and provide a clear alternative
to authoritarian versions of AI that would deploy it to consolidate power.
In response to
these interested governments, OpenAI is offering a new kind of partnership for
the Intelligence Age. Through formalized infrastructure collaborations, and in
coordination with the US government, OpenAI will:
- Partner with countries to help build
in-country data center capacity. These secure data centers will help
support the sovereignty of a country’s data, build new local industries,
and make it easy to customize AI and leverage their data in a private and
compliant way.
- Provide customized ChatGPT to citizens. This
will help deliver improved healthcare and education, more efficient public
services, and more. This will be AI of, by, and for the needs of each
particular country, localized in their language and for their culture and
respecting future global standards.
- Continue evolving security and safety controls
for AI models. As our models become more powerful, we will continue to make
investments in the processes and controls, including the data center and
physical security needed to deploy, operate and protect them. As part of
AI safety, it is critical to respect democratic processes and human
rights; we are excited to collaborate on future directions for global
democratic input to shape AI.
- Together, raise and deploy a national start-up
fund. With local as well as OpenAI capital, together we can seed healthy
national AI ecosystems so the new infrastructure is creating new jobs, new
companies, new revenue, and new communities for each country while also
supporting existing public- and private-sector needs.
- Partner countries also would invest in
expanding the global Stargate Project—and thus in continued
US-led AI leadership and a global, growing network effect for democratic
AI.
As OpenAI moves
forward with OpenAI for Countries, our goal is to pursue 10 projects with
individual countries or regions as the first phase of this initiative, and
expand from there.
We look forward to
engaging with interested countries through their representatives in the US and
through our executives based in our offices around the world.
What is the
Stargate AI project?
The Stargate Project, as the venture is named, is a partnership
between four notable companies: OpenAI, SoftBank, Oracle and MGX. Its goal is
to construct sites throughout the U.S. to develop, power, deploy and maintain
AI technology.
What will the
Stargate Project do?
The Stargate project is a strategic collaboration between industry
giants, aiming to build the next generation of AI infrastructure. This
ambitious initiative will involve building massive data centers, expanding
computing power, and enhancing AI capabilities at an unprecedented scale.
New “OpenAI for
Countries” program reads less like a product launch and more like a handshake
with the future – sovereign AI infrastructure, tailored ChatGPT versions for
citizens, and a clear nudge toward AI that serves people, not power structures.
What’s interesting? They’re offering help with local data centers. Not just for
privacy, but to actually customize AI to the language, services, and values of
each country. 🇱🇻🇺🇦🇩🇰 It’s rare that a
big-tech move makes me think, “Wait, is this what ethical infrastructure might
look like?” Of course, there’s plenty to critique and plenty we still don’t
know. But the intent is crystal: “AI should strengthen democratic institutions,
not replace them.”
https://openai.com/global-affairs/openai-for-countries/
Criminal AI is Here—And Anyone Can Subscribe
A new AI platform
called Xanthorox markets itself as a tool for cybercrime, but its real danger
may lie in how easily such systems can be built—and sold—by anyone…:
https://www.scientificamerican.com/article/xanthorox-ai-lets-anyone-become-a-cybercriminal
Could AI Really Kill Off Humans?
Many people
believe AI will one day cause human extinction. A little math tells us it
wouldn’t be that easy…:
https://www.scientificamerican.com/article/could-ai-really-kill-off-humans
OpenAI insiders’ open letter warns of ‘serious risks’ and calls for
whistleblower protections
By Samantha Murphy Kelly, CNN
Tue
June 4, 2024
A
group of OpenAI insiders are demanding that artificial intelligence companies
be far more transparent about AI’s “serious risks” — and that they protect
employees who voice concerns about the technology they’re building.
“AI
companies have strong financial incentives to avoid effective oversight,” reads
the open letter posted Tuesday signed by
current and former employees at AI companies including OpenAI, the creator
behind the viral ChatGPT tool.
They
also called for AI companies to foster “a culture of open criticism” that
welcomes, rather than punishes, people who speak up about their concerns,
especially as the law struggles to catch up to the quickly advancing
technology.
Companies have acknowledged
the “serious risks” posed by AI — from manipulation to a loss of control, known
as “singularity,” that could potentially result in human extinction
— but they should be be doing more to educate the public about risks and
protective measures, the group wrote.
As the law currently stands, the
AI employees said, they don’t believe AI companies will share critical
information about the technology voluntarily.
It’s essential, then, for
current and former employees to speak up — and for companies not to enforce
“disparagement” agreements or otherwise retaliate against those who voice risk-related
concerns. “Ordinary whistleblower protections are insufficient because they
focus on illegal activity, whereas many of the risks we are concerned about are
not yet regulated,” the group wrote.
Their letter comes as
companies move quickly to implement generative AI tools into their products,
while government regulators, companies and consumers grapple with responsible
use. Meanwhile many tech experts, researchers and leaders have called for a temporary pause in the AI race, or for the
government to step in and create a moratorium.
OpenAI’s response
In
response to the letter, OpenAI spokesperson told CNN it is “proud of our track
record providing the most capable and safest AI systems and believe in our
scientific approach to addressing risk, adding that the company agrees
“rigorous debate is crucial given the significance of this technology.”
OpenAI
noted it has an anonymous integrity hotline and
a Safety and Security Committee led by members of its board and safety leaders
from the company. The company does not sell personal info, build user profiles,
or use that data to target anyone or sell anything.
But
Daniel Ziegler, one of the organizers behind the letter and an early
machine-learning engineer who worked at OpenAI between 2018 and 2021, told CNN
that it’s important to remain skeptical of the company’s commitment to transparency.
“It’s
really hard to tell from the outside how seriously they’re taking their
commitments for safety evaluations and figuring out societal harms, especially
as there is such strong commercial pressures to move very quickly,” he
said. “It’s really important to have the right culture and processes so that
employees can speak out in targeted ways when they have concerns.”
He
hopes more professionals in the AI industry will go public with their concerns
as a result of the letter.
Meanwhile,
Apple is widely expected to announce a partnership with OpenAI at its annual
Worldwide Developer Conference to bring generative AI to the iPhone.
“We
see generative AI as a key opportunity across our products and believe we have
advantages that set us apart there,” Apple CEO Tim Cook said on the company’s most recent
earnings call in early May. https://edition.cnn.com/2024/06/04/tech/openai-insiders-letter/index.html
AI Act: a step closer to the first rules on
Artificial Intelligence
11-05-2023
Once approved, they will be the world’s first rules on Artificial Intelligence
- MEPs include bans on biometric surveillance,
emotion recognition, predictive policing AI systems
- Tailor-made regimes for general-purpose AI and
foundation models like GPT
- The right to make complaints about AI systems
To ensure a human-centric and ethical development
of Artificial Intelligence (AI) in Europe, MEPs endorsed new transparency and risk-management
rules for AI systems…: https://www.europarl.europa.eu/news/en/press-room/20230505IPR84904/ai-act-a-step-closer-to-the-first-rules-on-artificial-intelligence
Why
We're Worried about Generative AI
From the technology upsetting jobs and causing intellectual property issues to models making up fake answers to questions, here’s why we’re concerned about generative AI.
Full
Transcript…: https://www.scientificamerican.com/podcast/episode/why-were-worried-about-generative-ai/
An Action Plan to increase the safety and security of advanced AI
In October
2022, a month before ChatGPT was released, the U.S. State Department
commissioned an assessment of proliferation and security risk from weaponized
and misaligned AI.
In February 2024, Gladstone completed that assessment. It includes an analysis
of catastrophic AI risks, and a first-of-its-kind,
government-wide Action Plan for what we can do about them.
https://www.gladstone.ai/action-plan#action-plan-overview
Artificial Intelligence Act: MEPs adopt landmark law
Facial recognition technology can expose
political orientation from naturalistic facial images
Abstract
Ubiquitous
facial recognition technology can expose individuals’ political orientation, as
faces of liberals and conservatives consistently differ. A facial recognition
algorithm was applied to naturalistic images of 1,085,795 individuals to
predict their political orientation by comparing their similarity to faces of
liberal and conservative others. Political orientation was correctly classified
in 72% of liberal–conservative face pairs, remarkably better than chance (50%),
human accuracy (55%), or one afforded by a 100-item personality questionnaire
(66%). Accuracy was similar across countries (the U.S., Canada, and the UK),
environments (Facebook and dating websites), and when comparing faces across
samples. Accuracy remained high (69%) even when controlling for age, gender,
and ethnicity. Given the widespread use of facial recognition, our findings
have critical implications for the protection of privacy and civil liberties….:
https://www.nature.com/articles/s41598-020-79310-1
How your data is
collected and what you can do about it
07-03-2025
Mobile apps and
social media platforms now let companies gather much more fine-grained
information about people at a lower cost.
You wake up in the
morning and, first thing, you open your weather app. You close that pesky ad
that opens first and check the forecast. You like your weather app, which shows
hourly weather forecasts for your location. And the app is free!
But do you know
why it’s free? Look at the app’s privacy settings. You help keep it free by
allowing it to collect your information, including:
·
What
devices you use and their IP and media access control addresses.
·
Information
you provide when signing up, such as your name, email address, and home
address.
·
App
settings, such as whether you choose Celsius or Fahrenheit.
·
Your
interactions with the app, including what content you view and what ads you
click.
·
Inferences
based on your interactions with the app.
·
Your
location at a given time, including, depending on your settings, continuous
tracking.
·
What
websites or apps that you interact with after you use the weather app.
·
Information
you give to ad vendors.
·
Information
gleaned by analytics vendors that analyze and optimize the app.
This type of data
collection is standard fare. The app company can use this to customize ads and
content. The more customized and personalized an ad is, the more money it
generates for the app owner. The owner might also sell your data to other
companies.
You might also
check a social media account like Instagram. The subtle price that you pay is,
again, your data. Many “free” mobile apps gather information about you as you
interact with them.
As an associate
professor of electrical and computer engineering and a doctoral student in
computer science, we follow the ways software collects information about
people. Your data allows companies to learn about your habits and exploit them.
It’s no secret
that social media and mobile applications collect information about you. Meta’s
business model depends on it. The company, which operates Facebook, Instagram,
and WhatsApp, is worth $1.48 trillion. Just under 98% of its profits come from
advertising, which leverages user data from more than 7 billion monthly users.
What your data is
worth
Before mobile
phones gained apps and social media became ubiquitous, companies conducted
large-scale demographic surveys to assess how well a product performed and to
get information about the best places to sell it. They used the information to
create coarsely targeted ads that they placed on billboards, print ads, and TV
spots.
Mobile apps and
social media platforms now let companies gather much more fine-grained
information about people at a lower cost. Through apps and social media, people
willingly trade personal information for convenience. In 2007—a year after the
introduction of targeted ads—Facebook made over $153 million, triple the
previous year’s revenue. In the past 17 years, that number has increased by
more than 1,000 times.
Five ways to leave
your data
App and social
media companies collect your data in many ways. Meta is a representative case.
The company’s privacy policy highlights five ways it gathers your data:
First, it collects
the profile information you fill in. Second, it collects the actions you take
on its social media platforms. Third, it collects the people you follow and
friend. Fourth, it keeps track of each phone, tablet, and computer you use to
access its platforms. And fifth, it collects information about how you interact
with apps that corporate partners connect to its platforms. Many apps and
social media platforms follow similar privacy practices.
Your data and
activity
When you create an
account on an app or social media platform, you provide the company that owns
it with information like your age, birth date, identified sex, location, and
workplace. In the early years of Facebook, selling profile information to
advertisers was that company’s main source of revenue. This information is
valuable because it allows advertisers to target specific demographics like
age, identified gender, and location.
And once you start
using an app or social media platform, the company behind it can collect data
about how you use the app or social media. Social media keeps you engaged as
you interact with other people’s posts by liking, commenting or sharing them.
Meanwhile, the social media company gains information about what content you
view and how you communicate with other people.
Advertisers can
find out how much time you spent reading a Facebook post or that you spent a
few more seconds on a particular TikTok video. This activity information tells
advertisers about your interests. Modern algorithms can quickly pick up
subtleties and automatically change the content to engage you in a sponsored
post, a targeted advertisement or general content.
Your devices and applications
Companies can also
note what devices, including mobile phones, tablets, and computers, you use to
access their apps and social media platforms. This shows advertisers your brand
loyalty, how old your devices are, and how much they’re worth.
Because mobile
devices travel with you, they have access to information about where you’re
going, what you’re doing, and who you’re near. In a lawsuit against Kochava
Inc., the Federal Trade Commission called out the company for selling customer
geolocation data in August 2022, shortly after Roe v. Wade was overturned by
the Supreme Court in Dobbs v. Jackson Women’s Health Organization. Kochava’s
customers, including people who had abortions after the ruling was overturned,
often didn’t know that data tracking their movements was being collected,
according to the commission. The FTC alleged that the data could be used to
identify households.
Kochava has denied
the FTC’s allegations.
Information that
apps can gain from your mobile devices includes anything you have given an app
permission to have, such as your location, who you have in your contact list,
or photos in your gallery.
If you give an app
permission to see where you are while the app is running, for instance, the
platform can access your location anytime the app is running. Providing access
to contacts may provide an app with the phone numbers, names, and emails of all
the people you know.
Cross-application
data collection
Companies can also
gain information about what you do across different apps by acquiring
information collected by other apps and platforms.
This is common
with social media companies. This allows companies to, for example, show you
ads based on what you like or recently looked at on other apps. If you’ve
searched for something on Amazon and then noticed an ad for it on Instagram,
it’s probably because Amazon shared that information with Instagram.
This combined data
collection has made targeted advertising so accurate that people have reported
that they feel like their devices are listening to them.
Companies,
including Google, Meta, X, TikTok, and Snapchat, can build detailed user
profiles based on collected information from all the apps and social media
platforms you use. They use the profiles to show you ads and posts that match
your interests to keep you engaged. They also sell the profile information to
advertisers.
Meanwhile,
researchers have found that Meta and Yandex, a Russian search engine, have
overcome controls in mobile operating system software that ordinarily keep
people’s web-browsing data anonymous. Each company puts code on its web pages
that used local IPs to pass a person’s browsing history, which is supposed to
remain private, to mobile apps installed on that person’s phone, de-anonymizing
the data. Yandex has been conducting this tracking since 2017, while Meta began
in September 2024, according to the researchers.
What you can do
about it
If you use apps
that collect your data in some way, including those that give you directions,
track your workouts, or help you contact someone, or if you use social media
platforms, your privacy is at risk.
Aside from
entirely abandoning modern technology, there are several steps you can take to
limit access, at least in part, to your private information.
Read the privacy
policy of each app or social media platform you use. Although privacy policy
documents can be long, tedious, and sometimes hard to read, they explain how
social media platforms collect, process, store, and share your data.
Check a policy by making sure it can answer three questions: what data does the app collect, how does it collect the data, and what is the data used for. If you can’t answer all three questions by reading the policy, or if any of the answers don’t sit well with you, consider skipping the app until there’s a change in its data practices.
Remove unnecessary
permissions from mobile apps to limit the amount of information that
applications can gather from you.
Be aware of the
privacy settings that might be offered by the apps or social media platforms
you use, including any setting that allows your personal data to affect your
experience or shares information about you with other users or applications.
These privacy
settings can give you some control. We recommend that you disable “off-app
activity” and “personalization” settings. “Off-app activity” allows an app to
record which other apps are installed on your phone and what you do on them.
Personalization settings allow an app to use your data to tailor what it shows
you, including advertisements.
Review and update
these settings regularly because permissions sometimes change when apps or your
phone update. App updates may also add new features that can collect your data.
Phone updates may also give apps new ways to collect your data or add new ways
to preserve your privacy.
Use private
browser windows or reputable virtual private networks software, commonly
referred to as VPNs, when using apps that connect to the internet and social
media platforms. Private browsers don’t store any account information, which
limits the information that can be collected. VPNs change the IP address of
your machine so that apps and platforms can’t discover your location.
Finally, ask
yourself whether you really need every app that’s on your phone. And when using
social media, consider how much information you want to reveal about yourself
in liking and commenting on posts, sharing updates about your life, revealing
locations you visited, and following celebrities you like.
https://www.fastcompany.com/91361508/social-media-apps-data-collection-privacy
Data Collection
Basics and Available Resources
https://www.youtube.com/watch?v=m59H65a8p44
- 08-27-20
As a percentage of GDP, U.S. spending on scientific R&D has sunk to
levels not seen since the pre-Sputnik era.
NEXUS: A Brief History of Information Networks from the Stone Age to AI
Yuval Noah Harari
This non-fiction book looks through the long lens
of human history to consider how the flow of information has made, and unmade,
our world.
We
are living through the most profound information revolution in human history.
To understand it, we need to understand what has come before. We have
named our species Homo sapiens, the wise human – but if humans are
so wise, why are we doing so many self-destructive things? In particular, why
are we on the verge of committing ecological and technological suicide?
Humanity gains power by building large networks of cooperation, but the easiest
way to build and maintain these networks is by spreading fictions, fantasies,
and mass delusions. In the 21st century, AI may form the nexus for a new
network of delusions that could prevent future generations from even attempting
to expose its lies and fictions. However, history is not deterministic, and
neither is technology: by making informed choices, we can still prevent the
worst outcomes. Because if we can’t change the future, then why waste time
discussing it?
https://www.ynharari.com/book/nexus/ ; https://www.goodreads.com/book/show/204927599-nexus
Around the halls: What should
the regulation of generative AI look like?
Nicol Turner Lee, Niam Yaraghi, Mark MacCarthy, and Tom Wheeler Friday, June 2, 2023
We are living in a time of unprecedented advancements in generative artificial intelligence (AI), which are AI systems that can generate a wide range of content, such as text or images. The release of ChatGPT, a chatbot powered by OpenAI’s GPT-3 large language model (LLM), in November 2022 ushered generative AI into the public consciousness, and other companies like Google and Microsoft have been equally busy creating new opportunities to leverage the technology. In the meantime, these continuing advancements and applications of generative AI have raised important questions about how the technology will affect the labor market, how its use of training data implicates intellectual property rights, and what shape government regulation of this industry should take. Last week, a congressional hearing with key industry leaders suggested an openness to AI regulation—something that legislators have already considered to reign in some of the potential negative consequences of generative AI and AI more broadly. Considering these developments, scholars across the Center for Technology Innovation (CTI) weighed in around the halls on what the regulation of generative AI should look like.
NICOL
TURNER LEE (@DrTurnerLee)
Generative AI refers to machine learning algorithms that can create new content
like audio, code, images, text, simulations, or even videos. More recent focus
has been on its enablement of chatbots, including ChatGPT, Bard, Copilot,
and other more sophisticated tools that leverage LLMs to
perform a variety of functions, like gathering research for assignments,
compiling legal case files, automating repetitive clerical tasks, or improving
online search. While debates around regulation are focused on the potential
downsides to generative AI, including the quality of datasets, unethical
applications, racial or gender bias, workforce implications, and greater
erosion of democratic processes due to technological manipulation by bad
actors, the upsides include a dramatic spike in efficiency and productivity as
the technology improves and simplifies certain processes and decisions like
streamlining physician processing of
medical notes, or helping educators teach critical
thinking skills. There will be a lot to discuss around generative AI’s ultimate
value and consequence to society, and if Congress continues to operate at a
very slow pace to regulate emerging technologies and institute a federal
privacy standard, generative AI will become more technically advanced and
deeply embedded in society. But where Congress could garner a very quick win on
the regulatory front is to require consumer disclosures when AI-generated
content is in use and add labeling or some type of multi-stakeholder certification
process to encourage improved transparency and accountability for existing and
future use cases.
Once again, the European
Union is already leading the way on this. In its most recent AI Act,
the EU requires that AI-generated content be disclosed to consumers to prevent
copyright infringement, illegal content, and other malfeasance related to
end-user lack of understanding about these systems. As more chatbots mine,
analyze, and present content in accessible ways for users, findings are often
not attributable to any one or multiple sources, and despite some permissions
of content use granted under the fair use doctrine in
the U.S. that protects copyright-protected work, consumers are often left in
the dark around the generation and explanation of the process and results.
Congress should prioritize
consumer protection in future regulation, and work to create agile policies
that are futureproofed to adapt to emerging consumer and societal
harms—starting with immediate safeguards for users before they are left to,
once again, fend for themselves as subjects of highly digitized products and
services. The EU may honestly be onto something with the disclosure
requirement, and the U.S. could further contextualize its application vis-à-vis
existing models that do the same, including the labeling guidance
of the Food and Drug Administration (FDA) or what I have proposed in prior
research: an adaptation of the Energy
Star Rating system to AI. Bringing more transparency and accountability
to these systems must be central to any regulatory framework, and beginning
with smaller bites of a big apple might be a first stab for policymakers.
NIAM
YARAGHI (@niamyaraghi)
With the emergence of sophisticated artificial intelligence (AI) advancements,
including large language models (LLMs) like GPT-4, and LLM-powered applications
like ChatGPT, there is a pressing need to revisit healthcare privacy
protections. At their core, all AI innovations utilize sophisticated
statistical techniques to discern patterns within extensive datasets using
increasingly powerful yet cost-effective computational technologies. These
three components—big data, advanced statistical methods, and computing
resources—have not only become available recently but are also being
democratized and made readily accessible to everyone at a pace unprecedented in
previous technological innovations. This progression allows us to identify
patterns that were previously indiscernible, which creates opportunities for
important advances but also possible harms to patients.
Privacy regulations, most
notably HIPAA, were established to protect patient confidentiality, operating
under the assumption that de-identified data would remain anonymous. However,
given the advancements in AI technology, the current landscape has become
riskier. Now, it’s easier than ever to integrate various datasets from multiple
sources, increasing the likelihood of accurately identifying individual
patients.
Apart from the amplified risk
to privacy and security, novel AI technologies have also increased the value of
healthcare data due to the enriched potential for knowledge extraction.
Consequently, many data providers may become more hesitant to share medical
information with their competitors, further complicating healthcare data
interoperability.
Considering these heightened
privacy concerns and the increased value of healthcare data, it’s crucial to
introduce modern legislation to ensure that medical providers will continue
sharing their data while being shielded against the consequences of potential
privacy breaches likely to emerge from the widespread use of generative AI.
MARK
MACCARTHY (@Mark_MacCarthy)
In “The
Leopard,” Giuseppe Di Lampedusa’s famous novel of the Sicilian
aristocratic reaction to the unification of Italy in the 1860s, one of his
central characters says, “If we want things to stay as they are, things will
have to change.”
Something like this Sicilian
response might be happening in the tech industry’s embrace of
inevitable AI regulation. Three things are needed, however, if we do not want
things to stay as they are.
The first and most important
step is sufficient resources for agencies to enforce current law. Federal Trade
Commission Chair Lina Khan properly says AI
is not exempt from current consumer protection, discrimination, employment, and
competition law, but if regulatory agencies cannot hire technical staff and
bring AI cases in a time of budget austerity, current law will be a dead
letter.
Second, policymakers should
not be distracted by science fiction fantasies of AI programs developing
consciousness and achieving independent agency over humans, even if these
metaphysical abstractions are endorsed by
industry leaders. Not a dime of public money should be spent on these highly
speculative diversions when scammers and industry edge-riders are seeking to
use AI to break existing law.
Third, Congress should
consider adopting new identification, transparency, risk assessment, and
copyright protection requirements along the lines of the European Union’s
proposed AI
Act. The National Telecommunications and Information
Administration’s request
for comment on a proposed AI accountability framework and Sen.
Chuck Schumer’s (D-NY) recently-announced legislative
initiative to regulate AI might be moving in that direction.
TOM
WHEELER (@tewheels)
Both sides of the political aisle, as well as digital corporate chieftains, are
now talking about the need to regulate AI. A common theme is the need for a new
federal agency. To simply clone the model used for existing regulatory agencies
is not the answer, however. That model, developed for oversight of an
industrial economy, took advantage of slower paced innovation to micromanage
corporate activity. It is unsuitable for the velocity of the free-wheeling AI
era.
All regulations walk a
tightrope between protecting the public interest and promoting innovation and
investment. In the AI era, traversing this path means accepting that different
AI applications pose different risks and identifying a plan that pairs the
regulation with the risk while avoiding innovation-choking regulatory
micromanagement.
Such agility begins with
adopting the formula by which digital companies create technical standards
as the formula for developing behavioral standards: identify
the issue; assemble a standard-setting process involving the companies, civil
society, and the agency; then give final approval and enforcement authority to
the agency.
Industrialization was all
about replacing and/or augmenting the physical power of
humans. Artificial intelligence is about replacing and/or augmenting
humans’ cognitive powers. To confuse how the former was
regulated with what is needed for the latter would be to miss the opportunity
for regulation to be as innovative as the technology it oversees. We need
institutions for the digital era that address problems that already are
apparent to all.
Google and Microsoft are
general, unrestricted donors to the Brookings Institution. The findings,
interpretations, and conclusions posted in this piece are solely those of the
author and are not influenced by any donation.
A shocking insight into how a country's citizens are kept "obedient"
A smartphone smuggled out of North Korea offers a glimpse into the bizarre world of totalitarian control and extreme censorship that the reclusive country uses to keep its citizens obedient.
The state's Orwellian control is not limited to the streets or conversations. It has even managed to squeeze it into the smartphones in people's pockets.
According to Martin Williams, a North Korea technology analyst, the state is using smartphones as indoctrination tools — small, handheld loyalty checks that double as surveillance devices. And the worrying thing is, it’s working! North Korea is starting to win its internal information war not by completely blocking foreign content, but by making people too afraid to engage with it at all.
https://www.youtube.com/watch?v=3olqrQtjPfc
In the digital age, such a scenario can happen in any totalitarian & autocratic country!
Martin Burkhardt
Eine kurze
Geschichte der Digitalisierung
Von
elektrisierten Mönchen zur künstlichen Intelligenz: Die Geistesgeschichte der
Maschine
Wir
erleben täglich das Wechselbad der Gefühle: Digitalisierungsbegeisterung und
Furcht vor der fremden kalten Macht. Doch woher kommt sie, diese Macht? Der
Kulturtheoretiker Martin Burckhardt zeigt: alles ist von Menschen erdacht.
Schließlich begann das digitale Zeitalter 1746. Wir würden nicht im Internet surfen,
hätte Abbé Nollet damals nicht die Sofortwirkung von Elektrizität entdeckt.
Hätte Joseph-Marie Jacquard nicht den automatisierten Webstuhl erfunden und
Charles Babbage mit seiner Analytischen Maschine nicht den Grundstein für
unseren heutigen Computer gelegt. Nicht die Mathematik treibt die
Digitalisierung voran, sondern menschliche Wünsche und Sehnsüchte. Dieses Buch
ist eine Einladung, den Computer nicht als Gerät zu denken, sondern als
Gesellschaftsspiel, das unsere Zukunft prägen wird. Ein Crashkurs in der
Geistesgeschichte der Maschine…: https://www.amazon.com/Eine-kurze-Geschichte-Digitalisierung-German-ebook/dp/B07C3QDM4H
Nav komentāru:
Ierakstīt komentāru